[Yabam] SSE 도입을 통한 RDB 부하 감소 회고
서론
이번에 야밤이라는 서비스에서 폴링되는 API를 SSE와 Kafka 를 도입하면서 성능 개선한 회고를 풀 것이다.
야밤 서비스 소개

야밤 서비스는 대학 축제 주막 타게팅 테이블 오더 시스템이다. 현장에서 QR 을 통해서 사용자는 주문을 하고 주막 사장은 현장에 pos 기를 통해 주문 현황 및 요청 사항을 볼 수 있고 관리할 수 있다
서버 아키텍처

현재 야밤 서비스만을 위해 실행되는 서버들이다 흰색 영역은 Obserbility , CICD , dev 개발 목적의 서버들이고 나머지는 production 을 위해 띄워져 있는 서버들이다.
마침 집에 라즈베리파이가 여러개가 있어서 클라우드와 라즈베리파이 홈서버를 혼용해서 구성했다.
가게 관리 , 가게 정보 CRUD , 주문 CRUD 등등이 핵심 core server 인 yabam server 에서 역할을 맡는다.
구조는 Service Mesh 컴포넌트들이 있어서 MSA 구조인거 처럼 보이지만 처음부터 큰 규모가 아니기 때문에 핵심 core 서버를 분리하지 않았다.
실시간(real-time) API
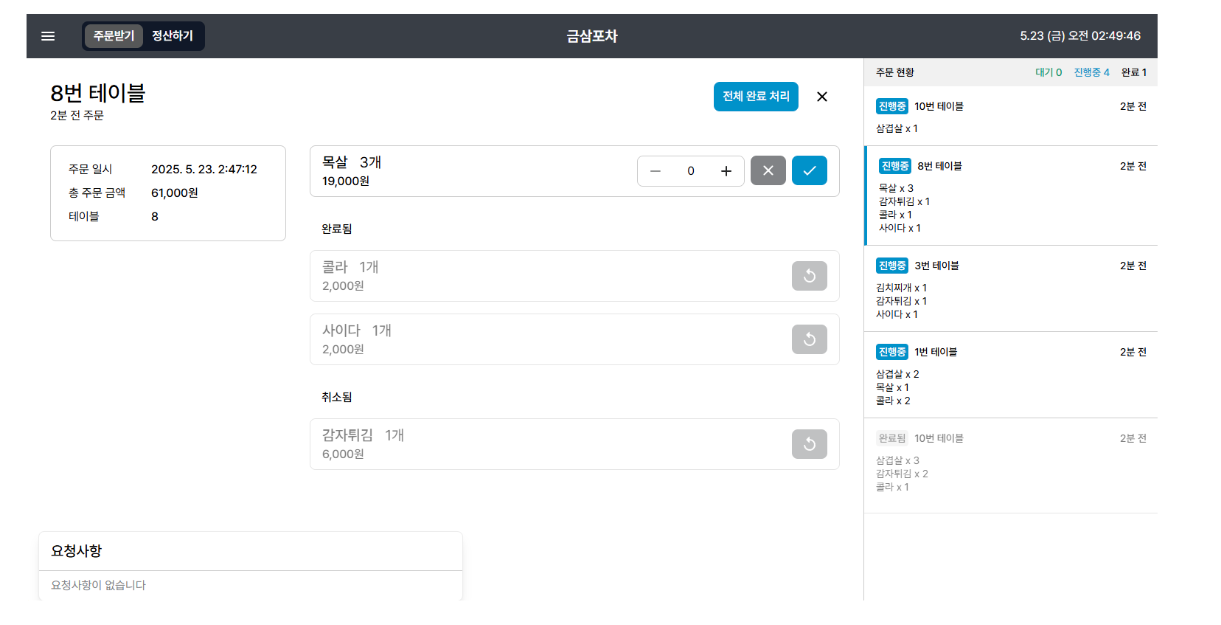
실제 사장 POS 기 화면이다. 위처럼 사장의 POS기는 사용자들이 주문한 주문이 실시간으로 들어와야하고, 주문의 상태 변화 또한 실시간(real-time)으로 변경되어야 한다.
또한 왼쪽 아래에 요청사항 또한 실시간으로 내역이 갱신되어야 한다.
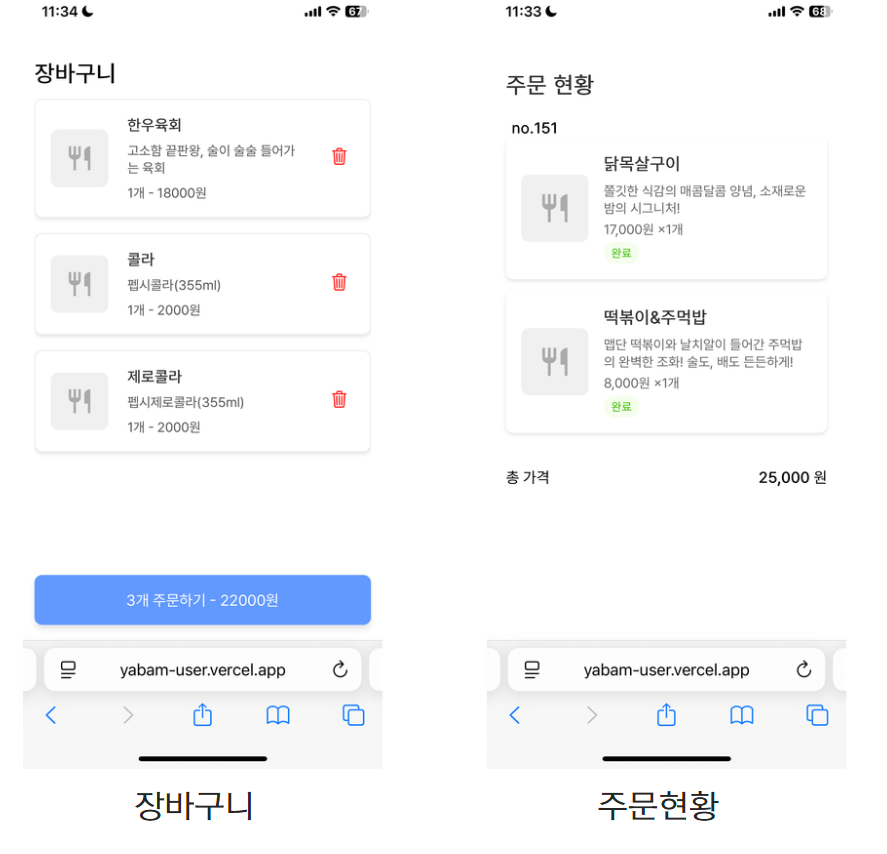
qr을 통해서 주문할 때도 함께 주문이 가능하기 때문에 장바구니와 주문 현황이 실시간으로 공유된다.
Polling 과 트러블
지금까지 야밤 서비스에서 사용하는 실시간을 보장해야하는 API 를 살펴보았다.
그럼 이런 실시간 갱신은 어떻게 구현해야 할까
Short Polling
이미지 출처: Spring에서 Server-Sent-Events 구현하기
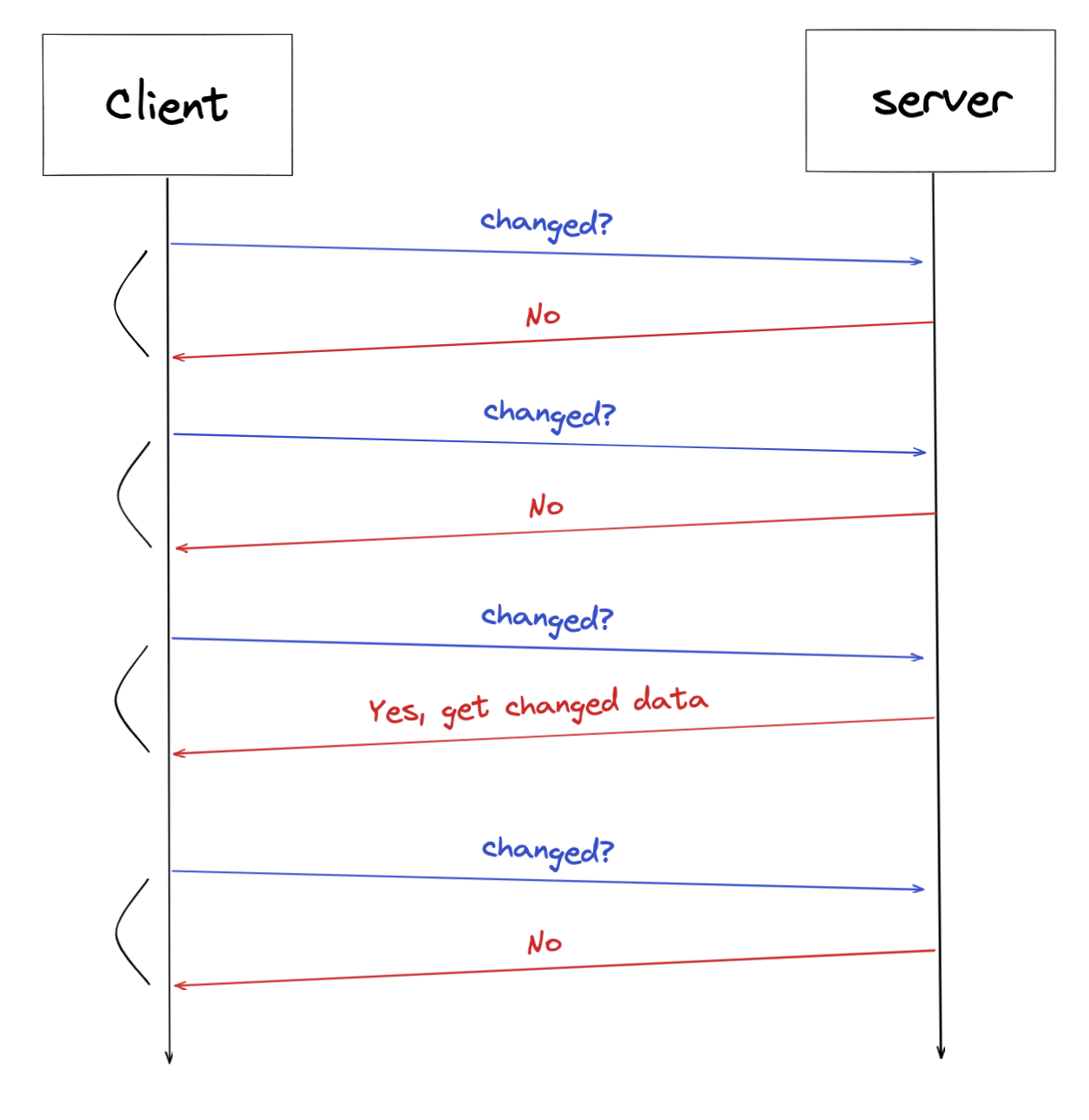
제일 구현하기 쉽고 구조적으로도 간단한 방법이다.
client 는 정해진 시간(보통 1s~1.5s) 마다 server 에게 데이터 조회 api 를 요청한다.
server는 1초마다 client 에게 최신 데이터를 전달하기 때문에 사용하는 유저에게는 실시간으로 데이터가 갱신되는 것처럼 보인다.
Polling 의 치명적 단점
polling 은 간단한 구현 방법이다. 그래서 처음 배포 때는 야밤 서비스 또한 polling 을 통해 실시간 서비스를 구현했다.
실제로 1차 배포때 생긴 장애 포인트를 보면서 이유를 추론해보자


위 사진을 보면 실제로 경험했던 장애 상황이다.
평소에 괜찮지만 특정 순간 DB가 부하를 감당하지 못하고 종료됐던 모습이다.
주문 트래픽이 MySQL 자원이 견디기 힘든 수준으로 몰린 것 아니냐라고 생각할 수 있다.
하지만 현재 MySQL 에 할당된 자원(CPU 4core , Mem 8GB) 에 비해 적은 트래픽이었다.
배포전 주문 부하 테스트를 했을 때의 기대 트래픽보다 못미치는 수준의 트래픽에서 MySQL 이 부하가 생겼다.
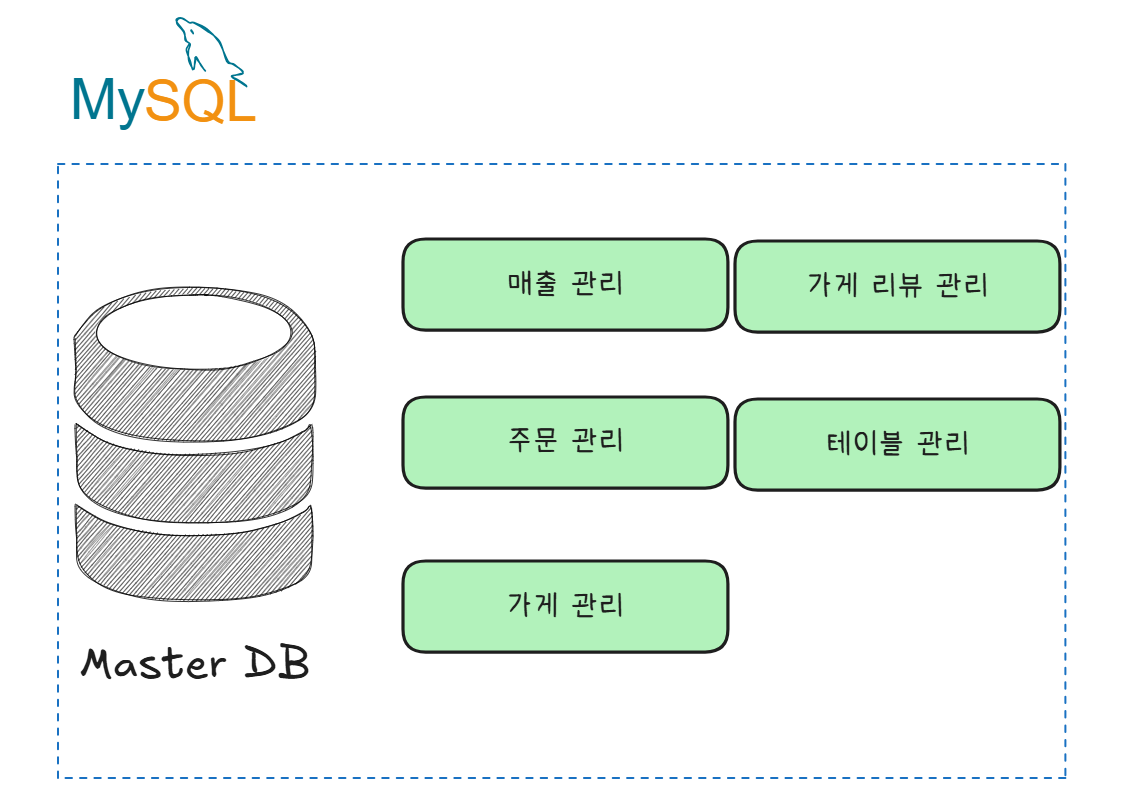
이러한 일이 발생한 이유는 MySQL DB 의 여러가지 역할의 데이터들이 모여있기 때문이다.
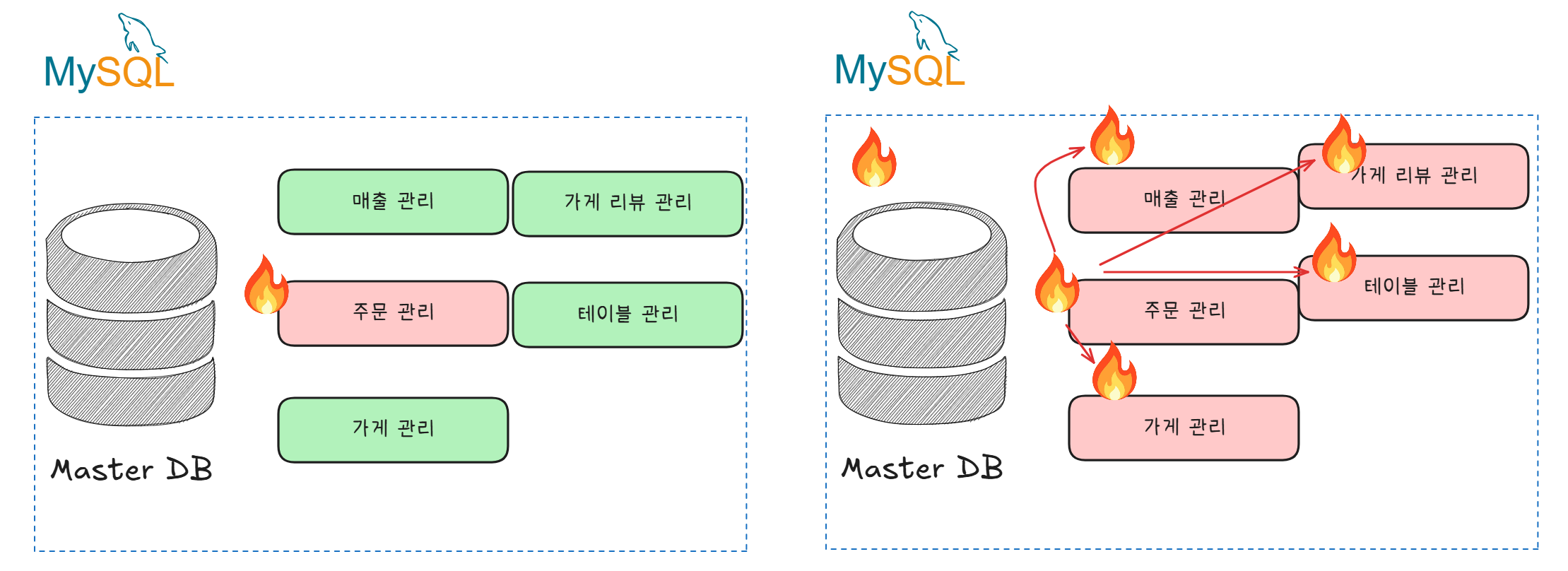
같은 DB에 다른 역할의 데이터가 모여 있어서 주문관리에서 생기는 Polling 부하는 독립적이지 않고 다른 API 에 영향을 줄 수 밖에 없다.
이에따른 전체 시스템에 장애 그리고 성능 저하를 경험하게 된다
여러가지 해결 방법들
DB의 부하가 문제이니 DB부하를 낮추는 방법을 생각해보자
캐싱
DB 부하를 낮추는 아주 보편적인 방법이다.
캐싱된 데이터는 DB에 접근하지 않는다는 점에서 DB 부하를 낮출 수 있다. 하지만 모든 데이터를 캐싱에 적용할 수 있는게 아니다. 특히 자주 변하는 데이터는 캐싱을 했다가는 데이터 만료 때문에 더 높은 비용에 읽기 혹은 쓰기 작업을 치룰 수 있다.
캐싱을 적용하기에는 야밤 실시간 데이터의 특성상 제한 사항이 있다고 판단했다.
MSA 도입과 함께 DB 분리
DB를 분리하면 된다 주문 DB, 테이블 DB , 리뷰 DB 이런식으로 나누고 서비스들도 역할에 맡게 나누면 되지만 이 방법은 우리 프로젝트 규모 특성상 이르다고 판단했다.
DB Replication 과 CQRS

MySQL Replication 을 활용하여 조회에 대한 API 쿼리는 Replica 된 DB로 쓰기 혹은 읽기는 Master DB로만 하게 하는 방법이 있다
이 방법은 과도한 조회에 대한 Master DB 부하를 줄여줄 수 있다는 점에서 긍정적으로 생각한다.
실시간 프로토콜 사용
지금까지 위 방법들은 실시간성 기능을 위해 polling 하는 것에서 생긴 문제점을 완화하는 목적이며 과도한 polling 부하는 근본적으로 해결되지 않는다.
물론 부하를 낮추기 위해 Long Polling 같은 방법도 있긴하겠지만 이방법 또한 근본적인 문제를 해결하지 못한다
따라서 실시간 프로토콜을 사용하면 과도한 polling 을 해결할 수 있다
Real-time protocal
왜 Rest API 는 실시간 통신이 안될까

우리가 흔히 사용하는 Rest API 방식은 클라이언트가 한 요청에 대한 Server 에 응답을 받는 구조이다.
이 말의 의미는 클라이언트가 요청하지 않으면 server 로부터 데이터를 받을 수 없음을 의미한다.
Rest API 와 다르게 서버로부터 데이터를 요청하지 않아도 받을 수 있는 프로토콜은 HTTP 프로토콜 위에서 동작하는건 SSE 와 Websocket 이 있다.
Server Side Event(SSE)
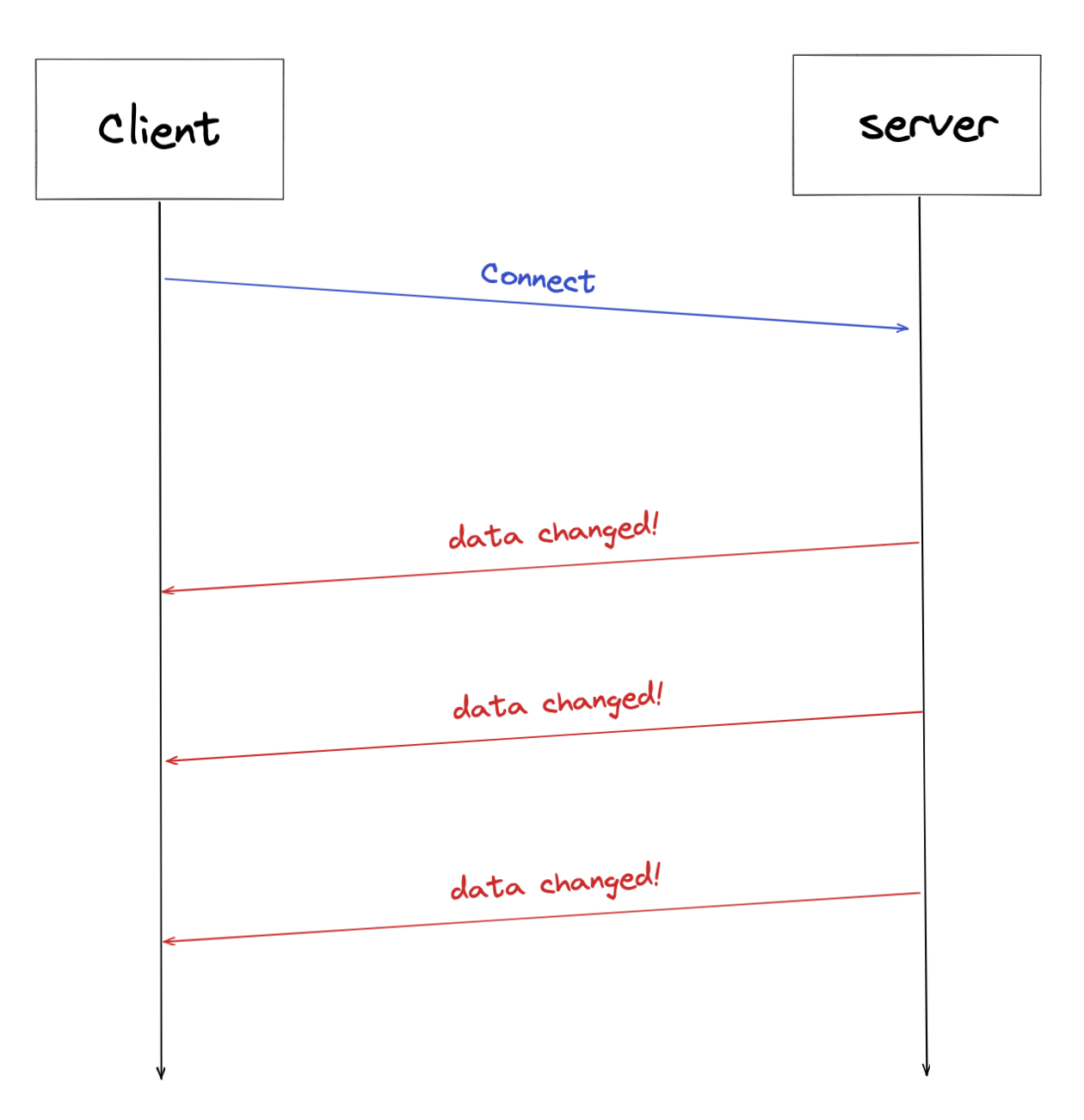
서버와 한번 연결을 맺고 나면 일정 시간동안 변경이 발생할 때마다 데이터를 전송받는 방법이다.
SSE 는 서버에서 클라이언트로 text message 를 보내는 브라우저 기반 웹 애플리케이션 기수이며 HTTP의 persistent connections을 기반으로하는 HTML5 표준 기술이다.
비슷한 커넥션을 유지하면서 서버로 부터 데이터를 받기도 보내기도 하는 프로토콜인 Websocket이랑은 다르게 서버로부터 데이터를 받기만 할 수 있다.
SSE 통신 과정

- client : SSE Subscribe 요청
- Server: Subscription 에 대한 응답
- Server: 이벤트 전달
Polling → SSE 로 변환
해결책
결론은 Polling 에서 발생한 문제를 SSE로 변환하는 걸 선택했다.
Websocket 을 안 쓴 이유는 실시간 통신에서 서버로부터 데이터를 보낼 필요가 없기 때문에 Websocket같은 양방향 통신이 아닌 단방향 SSE 를 선택하였다.
물론 SSE도 사용하면서 DB Replication을 혼용해서 사용해도 되지만 이번에는 SSE만을 사용해서 어떻게 시스템을 설계했는지 이야기 한다.
SSE 서버 추가
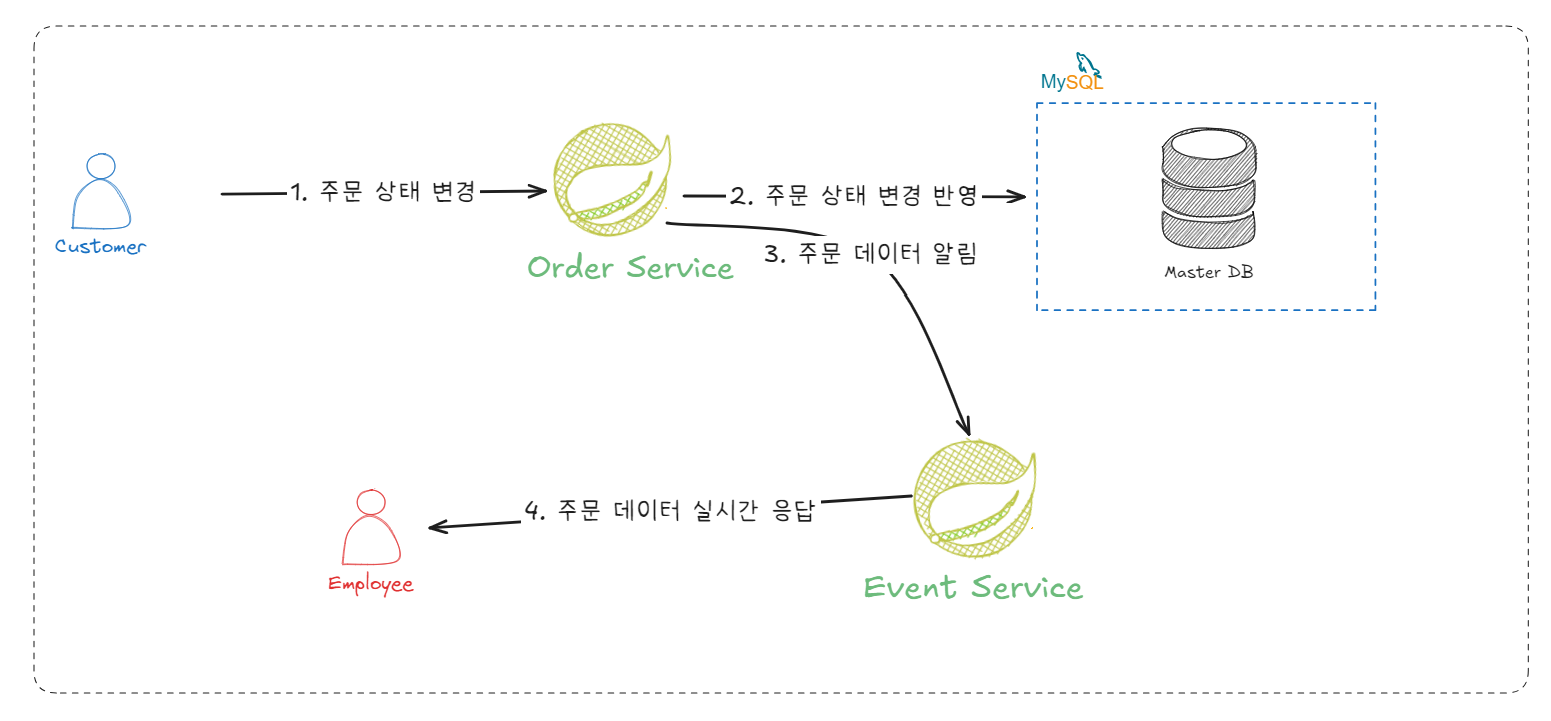
아주 단순한 구성이다. SSE 통신을 다루는 서버를 따로 실행하고 주문 관련 API 를 제공하는 서비스가 해당 서버에게 HTTP 요청을 보내는 방식이다.
하지만 여기에는 취약점이 존재한다.
확장에 닫혀있다.

이런 서버간에 직접 의존은 의존을 하는 서버가 증가되거나 삭제 되거나 할때마다 Order Service 에게 알려야 한다. (물론 Discovery 같은 service mesh로 어느정도 해결할 수 있다)
또한 증가된 Event Service 마다 주문 데이터 알림을 일일히 보내야한다. (왜냐하면 SSE 세션의 상태를 Order Service는 알 수 없으므로 어디에 해당 데이터를 보내야할지 모르기 때문)
Kafka 추가

Order 의 상태 변환 이벤트를 저장할 이벤트 브로커인 Kafka 를 도입하였다. Kafka는 안정성 높은 이벤트 브로커이면서 해당 토빅을 의존하는 컨슈머가 언제든지 자기가 읽은 이벤트부터 순차적으로 읽을 수 있다.
때문에 위처럼 Event Server 를 추가하더라도 Order Service는 항상 Kafka만을 의존하기 때문에 서버 간에 의존도는 낮춰진다
신뢰성과 안정성
해치웠나?
이제 사장 웹은 SSE 로 주문 내역을 받고 주문의 상태 변화는 Rest API 로 사용하면 된다. 그럼 이제 모든게 해결된 것일까?
메시지 유실 가능성

SSE 로만 사장 POS 시스템이 주문 변경 데이터를 수신한다면 위와 같은 상황이 발생할 수 있다. 연결 timeout 뿐 아니라 메시지 유실 네트워크 불안정으로 인한 disconnect 가 해당 상황에 놓인다.
위 예제에서 2번째 주문 데이터는 유실되게 된다.
이러한 메시지 유실 가능성은 Order 서버 와 kafka SSE 서버간에서도 발생할 수 있는데 이는 Kafka 의 At-most-once(최대 한번) ,At-least-once(최소 한번), Exatly-once(정확히 한번) 설정으로 할 수 있지만
클라이언트와 SSE 서버간에는 개선할 수 없다.
트레이드오프와 안정성
클라이언트와 SSE 서버간에 메시지 유실을 제거하기 위해서는 각 store 의 sale 마다 Sequence Number 를 부여하면 클라이언트에서는 어느 메시지가 유실된지 알 수 있을 것이다.
클라이언트에서 만약 유실을 감지했다면 해당 Seq num 을 rest api 로 호출해 받아올 수 있도록 한다.
하지만 이 방법은 구현의 난이도를 높인다. 따라서 당장의 개선을 확인할 수 있도록 fetch api 를 쓰도록 하였다.

위 방법을 쓴다면 메시지가 유실이 된다고 하더라도 fetch api 를 통해 유실된 데이터를 얻을 수 있다.
이러한 방법이 polling 과 비슷해서 성능도 비슷할거라고 판단할 수 있지만 timeout 을 도메인 특성상 치명적이지 않는 선에서 길게 선택한다면 시스템의 안정성 그리고 개발 난이도도 쉬워질 것이다.
회고
이번에 처음으로 실시간 서비스를 구현해보았다.
야밤이라는 프로젝트는 기획부터 1차 배포까지 기간이 타이트하였다. 처음 실시간 기능을 구현하기 위해 짧은 기간 때문에 최대한 빠른 개발을 할 수 있는 Short-Polling 방법을 채택하였다.
이번에 구현한 기능은 높은 성능의 실시간성과 데이터 일관성을 요구한다. (주문 데이터 내역이 오랫동안 안보이거나 누락된다면 대학교 축제 특성상 큰 혼란을 야기할 것이기 때문에...)
그래서 데이터 일관성과 빠른 개발 속도에 초점을 맞추었고 Short-Polling 을 사용했지만 장애와 성능 저하를 경험하였다....
데이터 일관성만 챙기고 성능과 가용성을 버리게 되었다... 그래서 구조를 개선의 필요성을 느꼇고 SSE 도입과 서버 분리, kafka mq를 도입하였다.
하지만 무작정 도입한다고 해결되지 않았다. 실시간성 데이터의 부하를 RDB를 통하지 않기 때문에 전체 시스템의 성능이 향상 됐지만 데이터 일관성 문제가 생기었고 분산 서버 간에 메시지 교환에서 발생할 수 있는 신뢰성 문제를 고민하는 계기가 되었다.
core 서버 <-> SSE 서버 <-> 클라이언트 간에 생길 수 있는 신뢰성 문제를 kafka 의 신뢰성 튜닝과 fetch api 도입을 하여 이를 해결했다.

실제로 RDB 성능 오버헤드가 없어졌기 때문에 처리율이 크게 상승했다.
하지만 아직 개선해야하는 점이 많이 보인다.
우선 fetch api 비용을 줄이는 것을 고민해 볼 것이다. 현재는 기존에 쓰였던 polling api로 fetch 하는데, 해당 api 비용이 크기 때문에 메시지를 생산하는 core server 에서 SequnceNumber 같은 것을 이용해 fetch api를 효율화 시킬 예정이다.
Kafka -> Redis Pub/Sub 으로 전환
Kafka를 선택한 이유는 Exactly Once 레밸의 메시지 신뢰성을 보장하기 위해서였다. 하지만 mq 레밸에서 신뢰성을 지킨다고 하더라도 클라이언트와 신뢰성이 안지켜질 수 있고 이를 fetch api 를 사용하기 때문에 Kafka 의 신뢰성 튜닝의 필요성이 낮아졌다.
또한 Kafka의 구조때문에 SSE 서버들이 자신과 세션을 맺고 있지않은 주문 데이터도 같이 consume 해야한다.
이러한 문제 때문에 Redis Pub/Sub 으로 migration 을 진행하고 성능을 측정해 볼 예정이다.