
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- SpringSecurity
- JPA
- 백준 장학금
- 멀티프로세서
- 최소힙
- 프로세스
- spring
- HTTP
- 백준장학금
- heapq
- 강화학습
- 자료구조
- 연결리스트
- python
- 점근적 표기법
- 엔티티 그래프
- Kruskal
- 알고리즘
- 이분탐색이란
- 연결리스트 종류
- 스케줄링
- JVM
- 운영체제
- jpa n+1 문제
- 완전이진트리
- MSA
- 최대 힙
- 힙트리
- AVL트리
- posix
- Today
- Total
KKanging
조회수 증가 로직 성능 측정 및 개선(43/s ⇒ 90/s) 본문
조회수 고민하기 시작한 계기
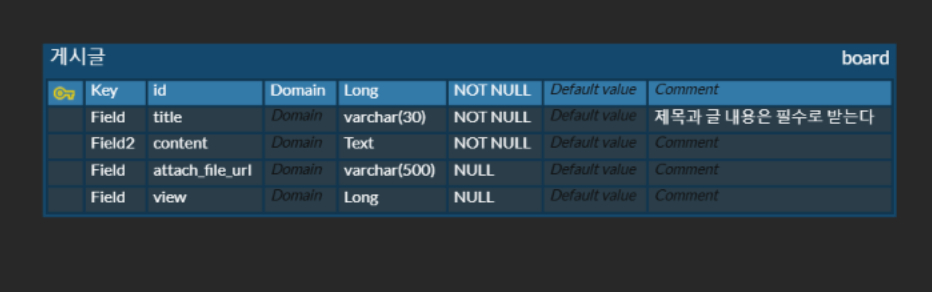
“필드에 view count를 저장하는 필드를 넣고 게시글을 조회할 때마다 count를 1증가 하면서 구현하면 되지 않나? “라고 생각할 수 있다
단순 필드에 1증가의 문제점
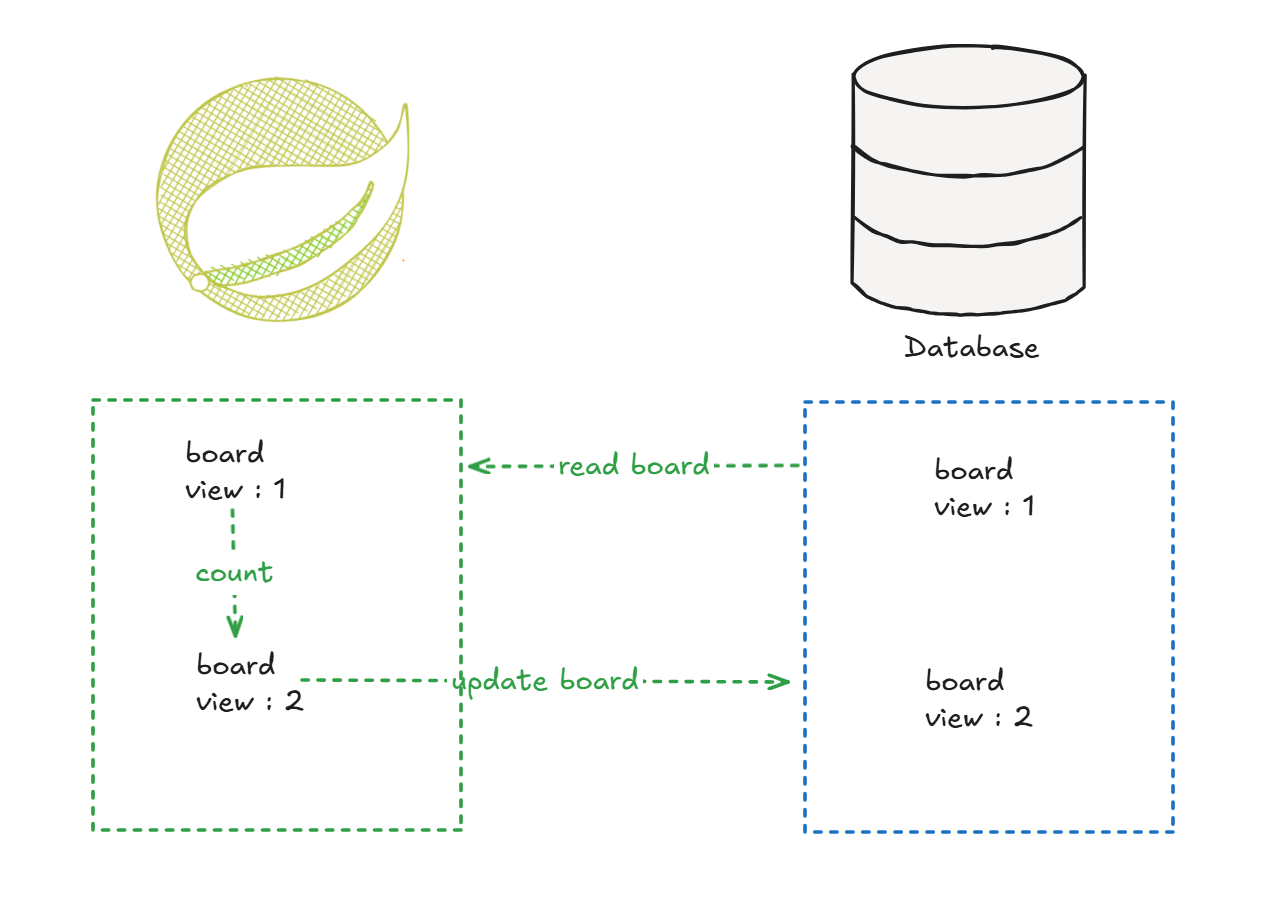
조회수 증가 로직을 보면 위와 같이 수행된다
게시글 데이터를 읽어오고 애플리케이션에서 1을 증가해서 update 하는 방식이다.
무슨 문제가 있을까?
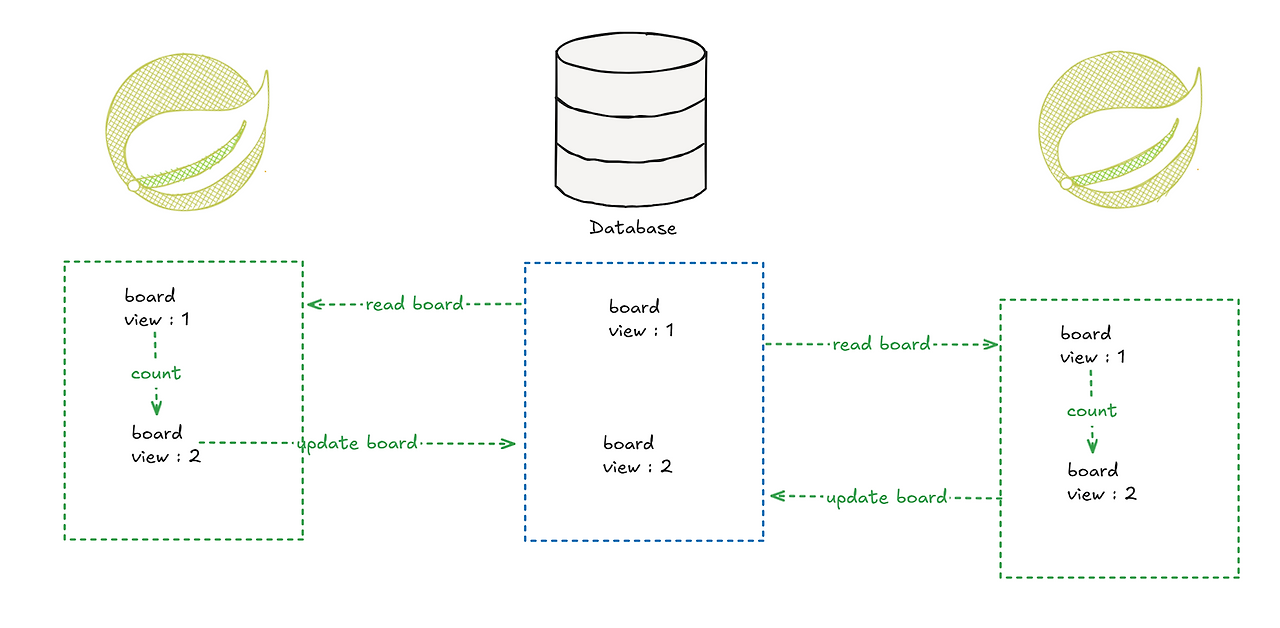
(위 그림은 모식화하기 위해 별개의 spring에서 실행된거 처럼 보이는데 같은 spring 서버 안에서 별개의 트랜잭션에서도 동일하다.)
위 그림과 같이 2번의 조회에 +2가 되어야하는데 1만 증가하는 Lost Update 현상이 발생하였다.
이러한 동시성 문제는 읽기의 동시성 문제를 해결하기 위한 MySQL 에서 제공하는 MVCC로도 해결할 수 없다.
이러한 동시성 문제는 애플리케이션에서 처리를 하거나 락을 사용하거나 해야한다.
따라서 다음과 같은 해결책을 생각해보았다.
조회수 증가 로직
조회수 증가 로직의 중요한 쟁점은 성능과 동시성 제어 2가지 쟁점에 초점을 맞추어야 한다.
따라서 다음과 같은 후보군을 생각했고 각각을 성능 테스트하여 비교 해보았다.
- 레코드 락을 이용한 조회수 증가
- view 테이블 생성해서 레코드를 쌓는 방식
- write Back 을 활용한 조회수 증가
테스트 환경
도메인 특성 상 게시물을 올릴 때 단기간에 많이 조회를 한다고 생각했다 ( 지속적인 조회보다는 단기간 조회의 영향이 크다고 생각했다)
이유는 게시물이 올라가고 알림과 단톡을 통한 공지를 올리기 때문에 단기간 조회가 많다고 생각했고, 큰 차이를 보고 싶기에 다음과 같은 환경에서 테스트 했다.
- api : 게시물 상세 조회 ( 조회마다 조회수 1 증가 조회수 제한에 대한 기획의 요청은 없었기에 이렇게 처리)
- 테스트: 1분에 약 1000명의 가상 사용자.
- 서버 환경 : core x 4 , memory 4gb , linux kernel
1. 레코드 락을 이용한 조회수 증가
구현
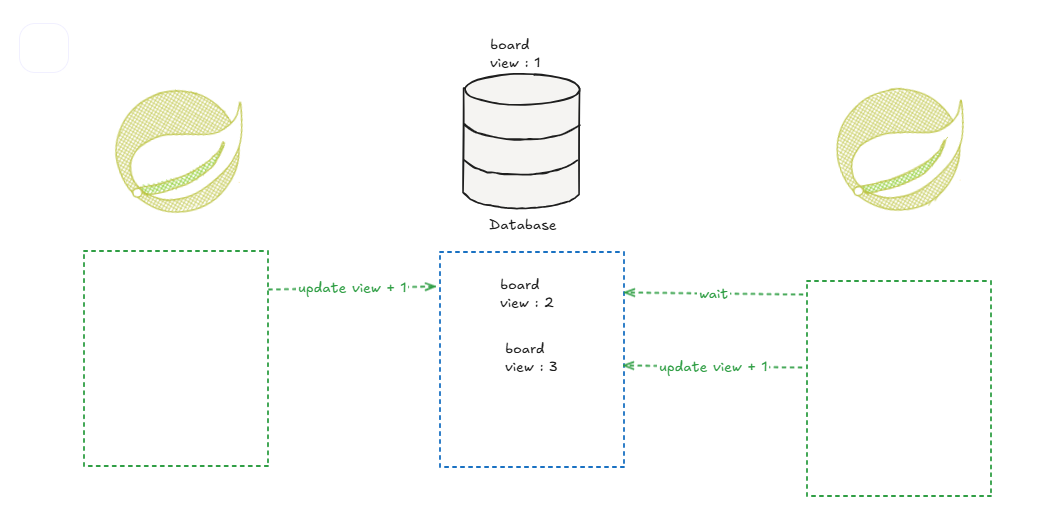
제일 구현이 쉬운 방법으로 사용해보았다.
board 테이블의 read 동작 없이 view 필드에 베타락을 걸었다
DB로는 MySQL 을 사용하고 있는데 MySQL에는 테이블 락이 아닌 락을 레코드 단위로 거는 레코드 락을 지원한다. (인덱스를 where 절에 사용했을 때)
따라서 다음과 같이 정의하였다.
@Transactional
@Modifying
@Query("UPDATE Board b SET b.viewCount = b.viewCount + 1 WHERE b.id = :boardId")
void increaseViewCount(@Param("boardId") Long boardId);예측
비관적 락을 사용하여 동시성 제어를 하는 것은 매우 일반적인 방법이다. 구현의 난이도도 제일 쉽다.
그리고 mysql 에서 지원하는 작은 범위의 레코드락은 매우 효율적이라고 판단했지만, 그래도 성능의 악영향을 주긴한다.
해당 board 테이블은 도메인 상에서 매인 페이지에서 쿼리로 요청이 오기도 하고 거기선 조회수를 보여주길 원하는 기획의 요청도 있었다.
따라서 아무리 작은 범위의 락이라도 해당 레코드를 접근하는 쿼리가 많기 때문에 현재 프로젝트 도메인에 성능에 영향이 많이 끼칠 것이라고 생각했다.
2. view 테이블 생성해서 레코드를 쌓는 방식
구현
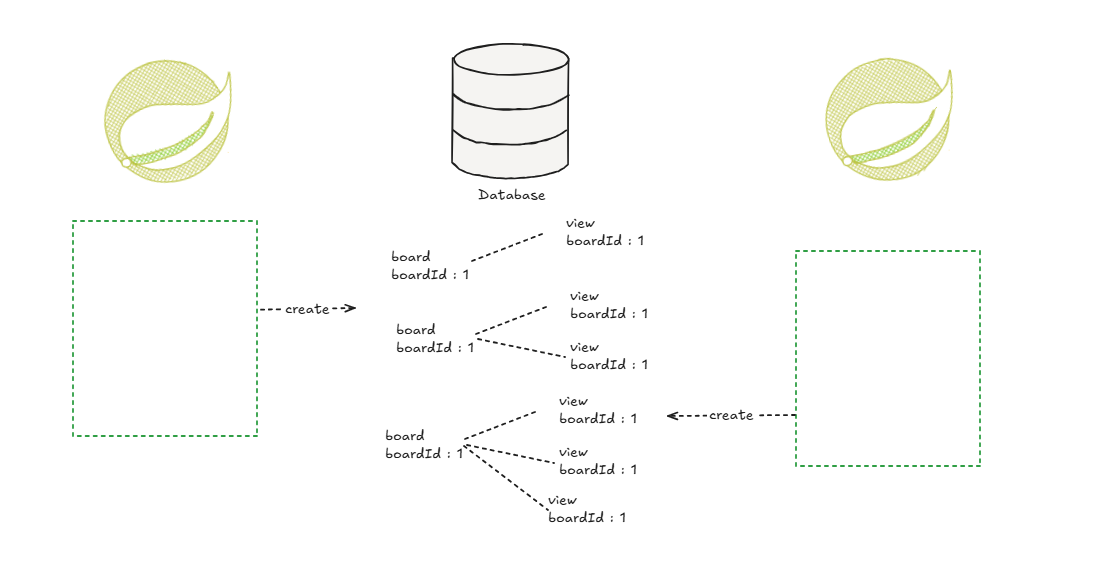
view 테이블을 하나 만들어서 board 테이블과 1:n 관계로 만드는 것이다.
그럼 한번의 조회수에는 하나의 view 레코드가 만들어지는 셈이다.
그리고 조회수를 통계를 낼 때는 count 집계 쿼리로 view 레코드의 수를 세는 식으로 조회를 한다.
수정 쿼리가 발생하지 않으므로 쓰기에 대한 동시성 이슈는 생기지 않는다. (boardId AutoIncreament 만의 아주 작은 pk 단계의 락말고는 락을 사용하지 않는다)
(생긴다 하더라도 Phantom Read 같은 Read 이슈는 생길만 하지만 MySQL의 MVCC Repeatable Read 에서는 발생하지 않고 발생한다고 하더라도 해당 도메인에서 큰 문제가 아니기 때문에 무시했다.)
예측
락도 사용하지 않으면서 구현 난이도 또한 쉽다.
락을 사용하지 않기 때문에 update 에 대한 성능이 개선될거 같다는 생각을 했다.
하지만 조회수를 계산하기 위한 count 함수로 모든 쿼리마다 계산을 해야하고, view 테이블 레코드가 많이 쌓인다는 점이 우려가 된다.
view 테이블의 레코드 데이터 각각은 의미가 없고 데이터의 수 만 의미가 있기 때문에 이러한 구조가 마음에 들지는 않았다.
그래도 1번째 구현보다는 성능이 좋을거라고 예측이 된다.
3. write Back 을 활용한 조회수 증가
구현
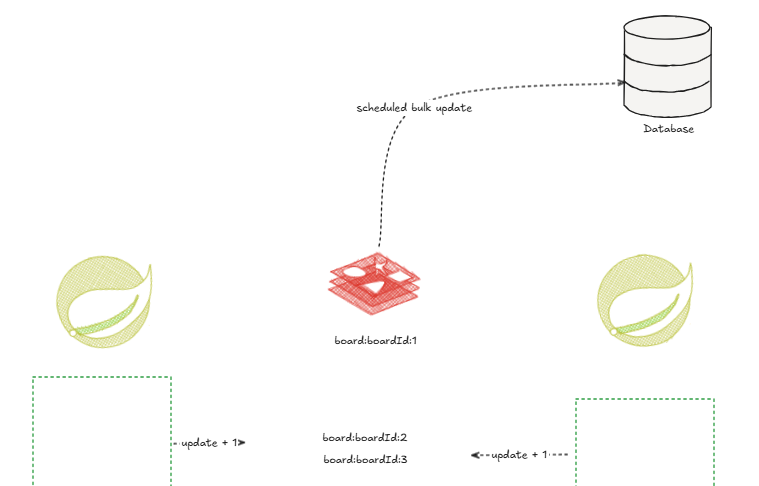
캐싱 작업 방식 중 하나인 write Back 을 사용해서 조회수 증가에 대한 update 로그를 캐싱하고 정해진 주기로 DB에 update 연산을 날리도록 설계했다.
조회수 증가가 되지 않았는데 update 쿼리를 날리지 않도록 Spring 에서 이벤트 드리븐 방식으로 조회마다 이벤트를
publish 하고 sub 하는 쓰레드가 정해진 시간( 분단위) 뒤에 update하도록 설계했다.
캐싱 서버로 사용한 redis는 싱글 쓰레드 기반이기 때문에 동시성 문제가 생기지 않는다.
예측
1번 방식의 단점인 update 에 의한 베타 락은 해당 구현에서는 정해진 시간에 딱 한번만 이루어진다. 따라서 1번 방식의 성능 저하를 크게 느끼지 못할 것이다.
2번 방식의 단점인 count 쿼리로 인한 view 집계 그리고 의미없는 view 레코드를 쌓는 것의 단점에서 극복할 수 있다.
하지만 단점이 아예 없는 것은 아니다 우선 redis 서버의 안정성을 신경을 써야한다. 안그럼 redis 서버가 다운되면 조회수를 집계할 수 없을 것이다. 장애 대응과 클러스터 같은 가용성과 안정성을 신경을 써야한다.
그리고 실시간으로 조회수가 증가하지 않는다. 하지만 이부분은 우리 도메인에서 실시간 조회수에 민감하지 않다. 따라서 몇분 정도 지연은 괜찮다고 판단하였다.
결과
각 실험을 다음 순서대로 실험하였다.
- 레코드 락을 이용한 조회수 증가
- view 테이블 생성해서 레코드를 쌓는 방식
- write Back 을 활용한 조회수 증가
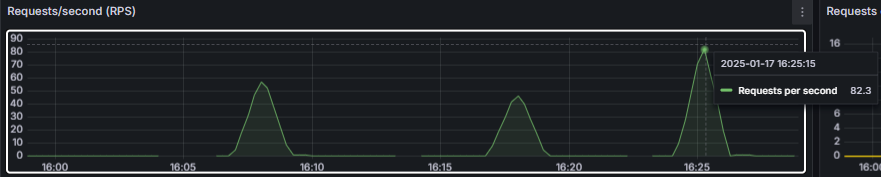
처리율 ( RPS )

write Back을 활용한 조회수 증가가 가장 높은 성능을 보였다.
지연율 (Latency)
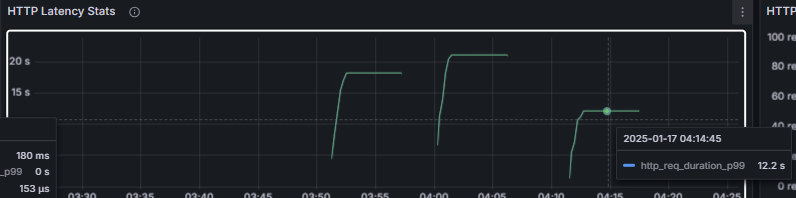

평균 응답 시간이나 최고 응답시간 또한 write Back을 활용한 조회수 증가가 가장 높은 성능을 보였다.
요약
|
테스트 번호
|
요청 완료 횟수
|
처리율 (요청/초)
|
평균 응답 시간 (초)
|
90% 응답 시간 (초)
|
95% 응답 시간 (초)
|
최대 응답 시간 (초)
|
|
1
|
4040
|
52.51/s
|
9.39s
|
15.57s
|
16.68s
|
22.05s
|
|
2
|
3547
|
45.30/s
|
10.93s
|
17.42s
|
18.87s
|
25.60s
|
|
3
|
5195
|
80.09/s
|
6.75s
|
10.78s
|
10.91s
|
14.59s
|
회고
write Back의 성능이 가장 좋을 것이라고 예상은 했지만, 2번째 테스트인 view 레코드 증가로 인한 조회수가 1번째 락을 이용한 조회수 증가보다 성능이 안좋을지는 예상하지 못했다.
물론 서비스를 껏다가 다시키고 실험을 시작한 시간이 3번째 보다 2번째가 짧아서 JVM warm up 시간이 안되어서 실험이 제대로 안되었나? 라고 생각했지만 3번째도 충분히 짧고 트래픽을 안보내고 테스팅한것은 똑같기 때문에 신경을 안써도 될듯하다.
원래는 2번째 방법으로 조회수 증가 로직을 구현했지만 항상 죄악을 저지른 기분이었다. 사실 구현 당시에 조회수라는 작은 영역에 신경쓰고 싶지 않아서 대충 구현한 경향이 있었기 때문이다.
배포 직전에 조회수 증가 로직에 대해 고민을 해보았고 아무리 생각해보아도 view 테이블을 만들어서 생기는 의미없는 레코드 수가 오버헤드로 다가와서 해당 테스트와 성능 개선을 시도했다.
다시 돌아간다고 하더라도 처음부터 write Back으로 조회수 로직을 구현하지 않을 듯하다.
이유는 초기 구현이 조회수의 실시간 성이라던가 redis의 안정성과 고가용성을 신경쓰면서 구현하는 것은 오버 엔지니어링 같기 때문이다.
다만 아쉬운 점은 조회수 필드 동시성 문제에 신경을 썻지만 락을 쓰는것에 극도록 신경을 썻던거 같다.
사실 락을 사용하는 것이 성능 저하의 주요 원인은 맞지만 너무 “락을 사용하지말자!” 에 집중 했었던거 같다 간단하고 빠르게 구현이 목적이었으면 그냥 락을 사용했을거 같다.
다음은 여러번 시도한 테스팅 결과이다. 똑같이 3번째 방식이 가장 성능이 좋았다.
'백엔드 > 시스템 설계 & 성능 개선' 카테고리의 다른 글
| [MSA] 서비스 게이트웨이(gateway) 란 (0) | 2025.02.17 |
|---|---|
| [MSA] 서비스 디스커버리 (0) | 2025.02.09 |
| [MSA로 전환기] Spring Cloud Config로 구성 파일을 분리하자 (0) | 2025.02.04 |


